几十年来,Atom融合和释放能量的复杂舞蹈一直让科学家们着迷。 现在,人类的聪明才智和人工智能正在美国能源部 (DOE) 普林斯顿Plasma物理实验室 (PPPL) 相结合,解决人类最紧迫的问题之一:通过聚变Plasma产生清洁、可靠的能源。
与传统的计算机代码不同,机器学习(一种人工智能软件)不仅仅是指令列表。 机器学习是一种可以分析数据、推断特征之间的关系、从新知识中学习并适应的软件。 PPPL 研究人员相信,这种学习和适应能力可以通过多种方式改善他们对聚变反应的控制。 这包括完善超热Plasma周围容器的设计、优化加热方法以及在越来越长的时间内保持反应的稳定控制。
该实验室的人工智能研究已经取得了显著成果。 在《自然通讯》上发表的一篇新论文中,PPPL 研究人员解释了他们如何使用机器学习来避免磁扰动或干扰,从而破坏聚变Plasma的稳定性。
该论文的主要作者、PPPL 研究物理学家 SangKyeun Kim 表示:“结果特别令人印象深刻,因为我们能够使用相同的代码在两个不同的托卡马克装置上实现这些结果。” 托卡马克是一种环形装置,利用磁场来保持Plasma。
“Plasma中存在不稳定性,可能会导致聚变装置严重损坏。我们不能在商业聚变容器中使用这些物质。我们的工作推动了该领域的发展,并表明人工智能可以在管理未来聚变反应方面发挥重要作用避免不稳定,同时让Plasma产生尽可能多的聚变能,”机械和航空航天工程系副教授 Egemen Kolemen 说道,他是安德林格能源与环境中心和 PPPL 联合任命的。
必须每毫秒做出重要决定,以控制Plasma并保持聚变反应持续进行。 科莱门的系统可以比人类更快地做出这些决定,并自动调整聚变容器的设置,以便正确维持Plasma。 该系统可以预测中断,找出需要更改的设置,然后在不稳定发生之前进行这些更改。
科尔曼指出,结果也令人印象深刻,因为在这两种情况下,Plasma都处于高限制模式。 也称为 H 模式,当磁约束Plasma被加热到足以使Plasma的约束突然显着改善并且Plasma边缘的湍流有效消失时,就会发生这种情况。 H 模式是最难稳定的模式,但也是商业发电所必需的模式。
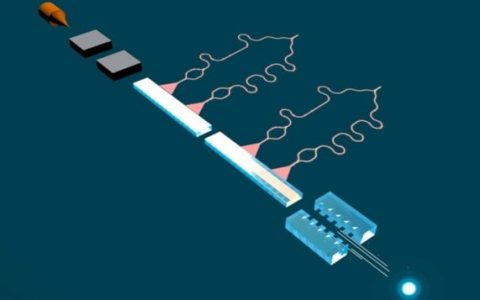
该系统成功部署在两个托卡马克装置上,DIII-D和KSTAR,它们都实现了H模式且没有不稳定。 这是研究人员首次在反应堆环境中实现这一壮举,该反应堆环境与商业规模部署聚变能所需的条件相关。
上面显示的两个托卡马克装置中部署了用于检测和消除Plasma不稳定性的机器学习代码:DIII-D 和 KSTAR。 (来源:通用Atom公司和韩国聚变能源研究所)
PPPL 在利用人工智能来应对不稳定方面有着悠久的历史。 PPPL 首席研究物理学家 William Tang 和他的团队于 2019 年第一个展示了将这一过程从一个托卡马克转移到另一个托卡马克的能力。
唐说:“我们的工作取得了突破,利用人工智能和机器学习以及强大的现代高性能计算资源,在千分之一秒内整合大量数据,并开发模型来在破坏性物理事件发生之前处理它们。” “你无法在超过几毫秒的时间内有效地对抗干扰。这就像在致命的癌症已经发展太久之后才开始治疗一样。”
2019 年《自然》杂志上发表的一篇有影响力的论文详细介绍了这项工作。Tang 和他的团队继续在这一领域开展工作,重点是使用经过适当验证和验证的观测数据训练的机器学习模型来消除托卡马克的实时中断。
仿星器设计的新变化
PPPL 的人工智能核聚变项目不仅限于托卡马克。 PPPL 数字工程主管 Michael Churchill 使用机器学习来改进另一种聚变反应堆(仿星器)的设计。 如果托卡马克看起来像甜甜圈,那么仿星器就可以被视为融合世界的油条,具有更复杂、更扭曲的设计。
“当我们验证仿星器的设计时,我们需要利用许多不同的代码。所以问题就变成了,‘仿星器设计的最佳代码是什么以及使用它们的最佳方法是什么?’”丘吉尔说。 “这是计算的详细程度和产生答案的速度之间的平衡行为。”
目前对托卡马克和仿星器的模拟已经接近真实情况,但还不是双胞胎。 “我们知道我们的模拟并不是 100% 真实的现实世界。很多时候,我们知道存在缺陷。我们认为它捕捉到了你在融合机上看到的很多动态,但还有很多但我们没有。”
丘吉尔说,理想情况下,你需要一个数字孪生:一个在模拟数字模型和实验中捕获的真实数据之间具有反馈回路的系统。 “在有用的数字孪生中,可以使用物理数据来更新数字模型,以便更好地预测未来的性能。”
毫不奇怪,模仿现实需要大量非常复杂的代码。 挑战在于代码越复杂,运行时间通常就越长。 例如,一种称为 X-Point Included Gyrokinetic Code(XGC)的常用代码只能在先进的超级计算机上运行,而且即使如此,它也不能快速运行。 “除非您有专用的百亿亿级超级计算机,否则您不会每次运行聚变实验时都运行 XGC。我们可能已经在 30 到 50 次等离子放电上运行过它 [of the thousands we have run],”丘吉尔说。
这就是丘吉尔使用人工智能来加速不同代码和优化过程本身的原因。 “我们真的很想进行更高保真度的计算,但速度要快得多,这样我们就可以快速优化,”他说。
编码以优化代码
同样,研究物理学家 Stefano Munaretto 的团队正在使用人工智能来加速名为 HEAT 的代码,该代码最初是由美国能源部橡树岭国家实验室和田纳西州诺克斯维尔大学为 PPPL 托卡马克 NSTX-U 开发的。
HEAT 正在更新,以便Plasma模拟将是 3D 的,与托卡马克偏滤器的 3D 计算机辅助设计 (CAD) 模型相匹配。 偏滤器位于聚变容器底部,可提取反应过程中产生的热量和灰烬。 3D Plasma模型应该可以增强对不同Plasma配置如何影响托卡马克中的热通量或热量运动模式的理解。 了解特定Plasma配置的热量运动可以深入了解未来类似Plasma放电中热量可能如何传播。
通过优化 HEAT,研究人员希望在等离子发射之间快速运行复杂的代码,利用上一次发射的信息来决定下一次发射。
“这将使我们能够预测下一次射击中出现的热通量,并有可能重置下一次射击的参数,这样热通量对于偏滤器来说不会太强烈,”穆纳雷托说。 “这项工作还可以帮助我们设计未来的聚变发电厂。”
PPPL 副研究物理学家 Doménica Corona Rivera 深入参与了 HEAT 优化工作。 关键是将输入参数的范围缩小到四到五个,这样代码就会精简但高度准确。 “我们必须问,‘这些参数中哪些是有意义的并且会真正影响热量?’”科罗娜·里维拉说。 这些是用于训练机器学习程序的关键参数。
在 Churchill 和 Munaretto 的支持下,Corona Rivera 已经大大减少了运行考虑热量的代码所需的时间,同时使结果与 HEAT 原始版本的结果保持大约 90% 的同步。 “这是瞬时的,”她说。
寻找理想加热的合适条件
研究人员还试图通过完善离子回旋射频加热(ICRF)技术来找到加热Plasma中离子的最佳条件。 这种类型的加热重点是加热Plasma中的大颗粒——离子。
Plasma具有不同的属性,例如密度、压力、温度和磁场强度。 这些特性改变了波与Plasma粒子相互作用的方式,并确定了波的路径和波将加热Plasma的区域。 量化这些效应对于控制Plasma的射频加热至关重要,这样研究人员就可以确保波有效地穿过Plasma,在正确的区域加热Plasma。
问题在于,用于模拟Plasma和无线电波相互作用的标准代码非常复杂,并且运行速度太慢,无法用于做出实时决策。
PPPL 副研究物理学家 Álvaro Sánchez Villar 表示:“机器学习为我们带来了优化代码的巨大潜力。” “基本上,我们可以更好地控制Plasma,因为我们可以预测Plasma将如何演化,并且我们可以实时纠正它。”
该项目的重点是尝试不同类型的机器学习来加速广泛使用的物理代码。 Sánchez Villar 和他的团队展示了针对不同聚变设备和加热类型的多个加速版本的代码。 这些模型可以在几微秒而不是几分钟内找到答案,并且对结果准确性的影响最小。 Sánchez Villar 和他的团队还能够利用机器学习通过优化的代码消除具有挑战性的场景。
Sánchez Villar 表示,该代码的准确性、“增强的鲁棒性”和加速性使其非常适合集成建模(其中许多物理代码一起使用)和实时控制应用,这对于聚变研究至关重要。
增强我们对Plasma边缘的理解
PPPL 首席研究物理学家法蒂玛·埃布拉希米 (Fatima Ebrahimi) 是美国能源部高级科学计算研究计划 (科学办公室的一部分) 为期四年的项目的首席研究员,该项目使用来自各种托卡马克的实验数据、Plasma模拟数据和人工智能来研究行为聚变过程中Plasma的边缘。 研究小组希望他们的发现能够揭示将Plasma限制在商业规模托卡马克上的最有效方法。
虽然该项目有多个目标,但从机器学习的角度来看,目标很明确。 “我们希望探索机器学习如何帮助我们利用所有数据和模拟,以便我们能够缩小技术差距,并将高性能Plasma集成到可行的聚变发电厂系统中,”埃布拉希米说。
世界各地的托卡马克装置收集了大量的实验数据,而这些装置在Plasma边缘没有大规模不稳定的状态下运行,称为边缘局域模式(ELM)。 需要避免这种瞬时爆炸性的 ELM,因为它们会损坏托卡马克的内部组件,将托卡马克壁上的杂质吸入Plasma中,并使聚变反应效率降低。 问题是如何在商业规模的托卡马克中实现无 ELM 状态,该托卡马克将比今天的实验托卡马克更大、运行温度更高。
Ebrahimi 和她的团队将把实验结果与Plasma模拟的信息结合起来,这些信息已经根据实验数据进行了验证,以创建一个混合数据库。 然后,该数据库将用于训练有关血浆管理的机器学习模型,然后可用于更新模拟。
“训练和模拟之间有一些来回,”埃布拉希米解释道。 通过在超级计算机上运行机器学习模型的高保真模拟,研究人员可以假设现有数据覆盖范围之外的场景。 这可以为在商业规模上管理Plasma边缘的最佳方法提供有价值的见解。
这项研究是利用以下能源部拨款进行的:DE-SC0020372、DE-SC0024527、DE-AC02-09CH11466、DE-SC0020372、DE-AC52-07NA27344、DE-AC05-00OR22725、DE-FG02-99ER54531、DE-SC0022270、 DE-SC0022272、DE-SC0019352、DEAC02-09CH11466 和 DE-FC02-04ER54698。 这项研究还得到了韩国聚变能源研究所 KSTAR 实验合作和聚变Plasma研究 (EN2401-15) 研究和设计项目的支持。
本故事包含约翰·格林沃尔德 (John Greenwald) 的贡献。
资讯来源:由a0资讯编译自THECOINREPUBLIC。版权归作者A0资讯所有,未经许可,不得转载